Protected presentation
Enter access code to continue
Confidential · All rights reserved · Nanometrix © 2026
Enter access code to continue
Confidential · All rights reserved · Nanometrix © 2026
New features, upcoming capabilities, and product roadmap.
Nanometrix
We provide software and workflow automation for labs and life sciences companies that need to analyse complex assay data faster, standardise outputs, and reduce the manual burden of internal or service-based work.
Tools for processing, analysing, and interpreting single-molecule data alongside orthogonal readouts such as ELISA, NTA, TEM, and other experimental datasets.
Workflows that reduce manual analysis, speed up results generation, and create consistent outputs for internal discovery, diagnostics, therapeutics, and CDMO-style work.
Co-developed tools built around specific internal bottlenecks, as well as platform support for facilities or companies offering services, including booking, analysis, and results delivery.
The major capabilities now live in the Nanometrix platform.
Access your data from anywhere, on any device. The offline software remains fully supported and continues to be an integral part of our enterprise offering for biotech and pharma.
Re-engineered back-end infrastructure to process datasets in parallel — process 1,000 datasets in seconds or minutes instead of waiting hours or days.
View, compare, filter, and run statistical tests in real time — all within the platform.
Export reports and datasets for further downstream analysis.
Each dataset ≈ 5M localisations · shorter is better
Online execution dispatches work across managed parallel compute — wall-clock stays roughly flat (≈ 30 s) while offline and Python scale with cohort size.
Features we're actively developing — categorised across the analysis workflow.
Lock beam point cloud files — go from microscope to results instantly
Fiducial-free redundant cross-correlation for structure-rich SMLM
Entropy minimisation — best default for localisation data
Separate channels from multi-colour simultaneous acquisition
AI-powered pass / warning / fail validation per dataset
Automatic flagging of striations, voids, and group-level outliers
New clustering method alongside existing DBSCAN
+/− controls, custom tags, and label-based result refinement
Side-by-side results and custom outputs for downstream tools
Publication-ready figure grids and custom image layouts
Ask questions in plain English — get graphs, insights, and validation
Ask questions in plain English. The agent creates graphs on demand, uncovers insights across populations, compares groups, sifts through your data, and validates findings — all grounded in your analysed cohort, not a generic model.
Create publication-quality plots on demand from your analysed library
Uncover patterns and relationships across populations automatically
Compare any N populations with statistical rigour
Automated statistical test selection and hypothesis checking
Navigate thousands of samples and metrics conversationally
In addition to deep context from your analysed cohort, the AI assistant can query real biological databases, analyse proteins, search literature, and more — all in real-time during conversation.
Accelerating data processing across modalities through strategic collaborations — converging into one unified platform.
A unified multi-modality platform accelerating data processing across all supported technologies.
Everything runs within AWS eu-west-2 (London). No data leaves AWS infrastructure. No third-party analytics. No tracking.
Your data stays within AWS eu-west-2 (London) at all times. Nothing leaves AWS infrastructure.
| Data | Storage | Retention |
|---|---|---|
| Uploaded datasets | S3, user-scoped folder | Until you delete |
| Processed files | S3, same user folder | Until parent deleted |
| Analysis results | S3 + DynamoDB | Until you delete |
| PDF reports | S3, reports folder | Until you delete |
| AI conversations | DynamoDB | User-managed |
| Account info | Cognito + DynamoDB | Until account closure |
Only summary statistics (counts, averages, test results) and your text prompts. Raw datasets are never read by the model. Bedrock runs in eu-west-2 — your data is not used to train models.
Only you can access your data. Platform administrators have limited access for support purposes only.
Your own datasets, analyses, reports, and AI conversations only
Account management, storage quotas, support-level data access
No cross-user data access. Unique storage paths per authenticated user.
Fully isolatedShared responsibility model. SOC 2 Type II certified. HTTPS enforced.
No data is shared with third parties. No external analytics. No ad networks. No model training.
Multiple layers of security protect your data at every stage — from upload to storage to access.
AWS Cognito with JWT sessions
Role-based tiers with feature gating
API-level authorisation on every request
Admin ops verified per request
AI restricted to authorised tiers
In transit: HTTPS (TLS) everywhere
S3 at rest: SSE-S3 encryption
DynamoDB: AWS owned keys
S3 versioning: 30-day retention
Access logging: All access recorded
DynamoDB PITR: 35-day recovery
Secure upload: Time-limited, authenticated transfers
Storage quotas: Enforced server-side
Usage tracking: Every upload/delete tracked
No hardcoded secrets: Credentials managed securely
S3 policy: Blocks non-HTTPS requests
Failures are contained, data is durable, and recovery mechanisms are built in at every layer.
Errors caught and recorded — no silent retries or duplicates
Failed jobs automatically detected and recovered
Data remains safe in S3 regardless
Fully managed, multi-AZ services — no self-managed servers
S3: 99.999999999% (11 nines) durability
CloudTrail: tamper-proof audit of all API calls
CloudWatch logs retained 12 months
Cognito brute-force detection & lockout
JWT auto-expiry limits exposure
S3 versioning: 30-day file recovery
DynamoDB PITR: 35-day restore
11 nines: Data loss virtually impossible
Technical security controls are strong. The organisational layer is actively being formalised.
| Area | Status |
|---|---|
| Authentication & identity | Strong |
| Data isolation | Strong |
| Operational resilience | Strong |
| Encryption (transit + rest) | Verified |
| Backup & recovery | Verified |
| Audit logging | Verified |
| MFA | In progress |
| Formal security policies | In progress |
| Dependency scanning | In progress |
| Formal certification | Starting |
We have implemented technical security controls that protect your data — authentication, isolation, encryption, quotas, and resilient processing.
The organisational layer — formal policies, compliance monitoring, and certification — is being built out. Security engineering is ahead of the paperwork.
Enforcing MFA for all users
Expanding JWT verification scope
Tightening CORS policy
Hardening error handling for production
Complete request lifecycle from researcher login through to encrypted storage — every action authenticated, every transfer encrypted.
flowchart TD
subgraph CLIENT["Web Application"]
USER["👤 Researcher"]
end
subgraph AUTH["Authentication Layer"]
COGNITO["AWS Cognito\n(User Pool + Identity Pool)"]
end
USER -->|"Login\n(email + password)"| COGNITO
COGNITO -->|"JWT token +\nscoped credentials"| USER
subgraph ACTIONS["Platform Capabilities"]
direction LR
UPLOAD["📤 Upload\nDatasets"]
PROJECT["📁 Manage\nProjects"]
ANALYSE["🔬 Run\nAnalysis"]
REPORT["📄 Generate\nReports"]
VIEW["📊 View\nResults"]
AI["🤖 AI\nAssistant"]
end
USER --> ACTIONS
subgraph SERVICES["Application Services (Serverless)"]
UPLOAD_SVC["Upload Service\n(auth-gated, quota-enforced)"]
PROCESS_SVC["Processing Service\n(queued, fault-tolerant)"]
REPORT_SVC["Report Service"]
AI_SVC["AI Service\n(restricted access)"]
end
UPLOAD --> UPLOAD_SVC
ANALYSE --> PROCESS_SVC
REPORT --> REPORT_SVC
AI --> AI_SVC
PROJECT --> DDB
VIEW --> DDB
UPLOAD_SVC -->|"Encrypted\ntransfer"| S3
UPLOAD_SVC --> DDB
PROCESS_SVC --> S3
PROCESS_SVC --> DDB
REPORT_SVC --> S3
REPORT_SVC --> DDB
subgraph AI_LAYER["AI Layer (eu-west-2)"]
BEDROCK["AWS Bedrock\n(summary data only,\nno raw datasets)"]
end
AI_SVC -->|"Summary\nstatistics only"| BEDROCK
BEDROCK -->|"Response"| AI_SVC
AI_SVC --> DDB
subgraph STORAGE["Encrypted Storage (eu-west-2)"]
S3[("Amazon S3\n━━━━━━━━━━\nSSE-S3 encrypted\nVersioned\nAccess logged")]
DDB[("DynamoDB\n━━━━━━━━━━\nEncrypted at rest\nPoint-in-time recovery\nUser-scoped")]
end
subgraph MONITORING["Audit & Monitoring"]
CT["CloudTrail\n(all API calls\nlog-validated)"]
CW["CloudWatch\n(application logs\nlong-term retention)"]
end
style CLIENT fill:#1e293b,stroke:#3b82f6,color:#fff
style AUTH fill:#1e293b,stroke:#22c55e,color:#fff
style ACTIONS fill:#1e293b,stroke:#a855f7,color:#fff
style SERVICES fill:#0f172a,stroke:#3b82f6,color:#fff
style AI_LAYER fill:#0f172a,stroke:#8b5cf6,color:#fff
style STORAGE fill:#0f172a,stroke:#22c55e,color:#fff
style MONITORING fill:#0f172a,stroke:#6b7280,color:#fff
Started working through Terasom's shared ELISA data
Built early app-style views for exploration
Reviewing structure, quality, trends, and comparisons
Identifying what could be automated or standardised
Next step: align outputs with Terasom's workflow and priorities
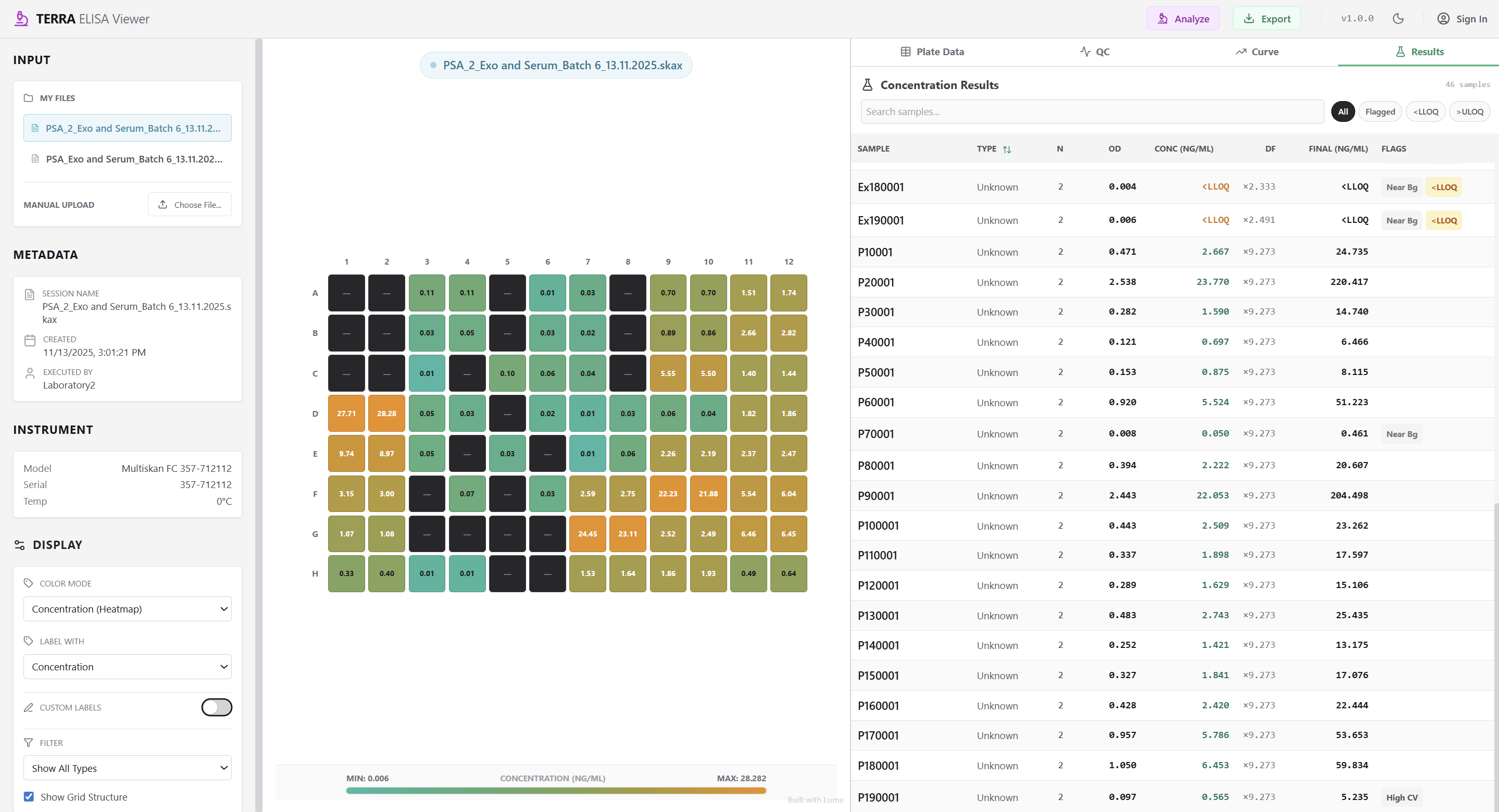
Key questions to help us understand where tools can have the most impact on Terasom's day-to-day work.
Understanding frequency and volume
Time from raw data to final outputs
Excel, Prism, bespoke scripts, LIMS, etc.
Bottlenecks and repetitive work
e.g. DLS, NTA, western blot, flow cytometry
QC, plots, reports, comparisons, insight
We are genuinely interested in developing this with Terasom. A collaborative approach ensures tools are shaped by real workflows and deliver practical value from day one.
First-mover advantage in shaping the platform
Preview builds and beta features before general release
Reports, analysis, and workflows tailored to your priorities
Built around what you actually do, not generic assumptions
Accelerate around Terasom use cases
Build around ELISA, DLS, and related outputs
Deliver early tools to agreed schedule
Optimise Terasom's pipeline quickly
Costs for dedicated dev time